The Power Duo: Embeddings and RAG in Practice – Part 2: RAG

Introduction
In my previous blog article, The Power Duo: Embeddings and RAG in Practice – Part 1: Embeddings, I introduced the concept of AI embeddings and how they can be used to enable machine learning models to find similar objects. We explored the practical side of embeddings and learned that they can enable a host of capabilities including semantic search, recommendation engines, finding similar documents, and data classification. Using the example of a recommendation feature for a blog, I demonstrated a practical implementation of using AI embeddings in an application, specifically on the Solution Street blog articles. If you haven’t read Part 1 of this blog series, I recommend starting there to get a good foundation of the concept of embeddings.
With an introductory understanding of embeddings and how they can be used in practical ways, let’s discuss another practical use of embeddings combined with generative AI to enable applications such as custom chatbots, customer support agents, and personalized content generation.
Introducing Generative AI and LLMs
Generative AI has revolutionized the field of natural language processing. Unless you have been living under a rock in the past year, you are almost certainly familiar with ChatGPT and maybe some other popular generative AI tools like DALL-E and other Large Language Models (LLMs). These models can generate human-like text (or other output like images, video, sound, etc.), making them incredibly useful for tasks such as answering general knowledge questions, generating content, and even writing code. However, a common challenge arises when we want these models to work with our own specific data that the LLM has not been trained on or is not allowed to access.
Consider this scenario: Imagine asking an LLM about the vacation policy at a fictitious company called SerpentTech Corporation. Since the underlying LLM was not trained on specific knowledge of this company, it can only provide a generic response.
Example 1: Generic Response
Prompt:
“What is the SerpentTech Corporation vacation policy?”
Response:
“SerpentTech Corporation’s vacation policy details may vary depending on their internal guidelines and the country they operate in. Typically, corporations like SerpentTech outline vacation policies in their employee handbooks or HR resources. Would you like help with more specific details or information on another company’s policies?”
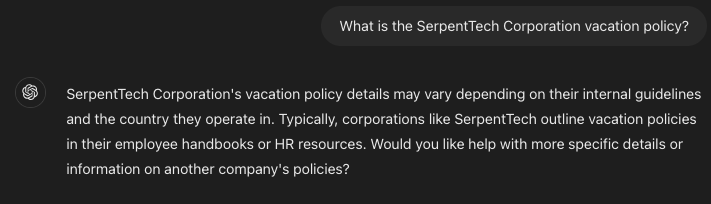
This response, while accurate in a very general sense, doesn’t provide the specific information requested.
Example 2: Contextualized Response
Now, let’s provide the LLM prompt with some additional context from the SerpentTech Corporation’s employee handbook.
Prompt:
“Using the information here about SerpentTech Corporation, and only this information, answer the following question: “What is the SerpentTech Corporation vacation policy?””
Context Provided:
“SerpentTech Corporation New Employee Handbook:
- Welcome to SerpentTech Corporation!
- We are a technology company that creates web applications using the programming language Python
- All employees are remote and are based all around the United States
- Employees are expected to be online and working Monday through Friday, from 9 AM ET to 5 PM ET
- Employees must report their time in the company timesheet system at the end of each day. All vacation time used in a time period is recorded in the PTO field
- All employees get 3 weeks (15 days) of vacation a year.
- You must request vacation at least one month before you plan on taking the vacation(s) day(s)
- Vacation days are called SerpentDays at SerpentTech Corporation”
Response:
“Based on the information provided in the SerpentTech Corporation New Employee Handbook:
SerpentTech Corporation Vacation Policy:
- Vacation Entitlement: All employees are entitled to 3 weeks (15 days) of vacation per year.
- Vacation Scheduling: Employees must request vacation at least one month in advance.
- Vacation Tracking: Vacation time used is recorded in the PTO (Paid Time Off) field of the company’s timesheet system.
- Work Schedule: Employees are expected to work remotely Monday through Friday, from 9 AM ET to 5 PM ET.
Additionally, vacation days at SerpentTech Corporation are referred to as “SerpentDays.”
This policy provides a structured framework for employees to plan and take their vacation time while ensuring operational continuity through advance scheduling and proper time tracking.”

As you can see, by providing more context and facts in the prompt, we can significantly increase the accuracy and reliability of the generative AI’s response. The context and facts can come from external sources, like the company handbook in this case, that are otherwise unknown to the LLM. This method of including facts in the context of the prompt also helps to prevent hallucinations, which are instances where the AI generates plausible-sounding but incorrect or nonsensical information.
Retrieval-Augmented Generation (RAG)
Providing more context in a prompt is a powerful way to enhance the accuracy of generated responses, especially when the information is not previously known to the model. However, what if we have a vast amount of data that contains the facts we need? For example, instead of a small company handbook, imagine having 20 GB of company policy and process data. It would be impractical to include all of this data in a single prompt due to the maximum limit on the size of the data you can include in a prompt which is known as a context window.
To intelligently select relevant data from a large amount of data, we can use a technique called Retrieval-Augmented Generation (RAG). RAG was first discussed in a 2020 paper by researchers at Meta (then Facebook). This technique combines the power of embeddings with generative AI to retrieve relevant snippets of data from a larger set, ensuring that only the necessary context is included in the prompt to generate an accurate response.
It is worth mentioning at this point that another alternative to getting the LLM to answer with previously unknown data is to retrain or fine-tune the LLM with the new information. While this approach can make the model inherently aware of the new data (and can produce better responses than the RAG approach), it is also very resource-intensive, requiring significant computational power and time. For these reasons, we will only focus on using the RAG technique in this article.
How RAG Works
RAG works by leveraging embeddings to find related data to include in the prompt. By generating embeddings from a large collection of data and then calculating the similarity of the data, we can identify the most semantically related data snippets to the question or information you are asking about in the prompt. These individual snippets are then included in the prompt to provide the generative AI with the necessary context.
Here’s a step-by-step breakdown of how RAG works:
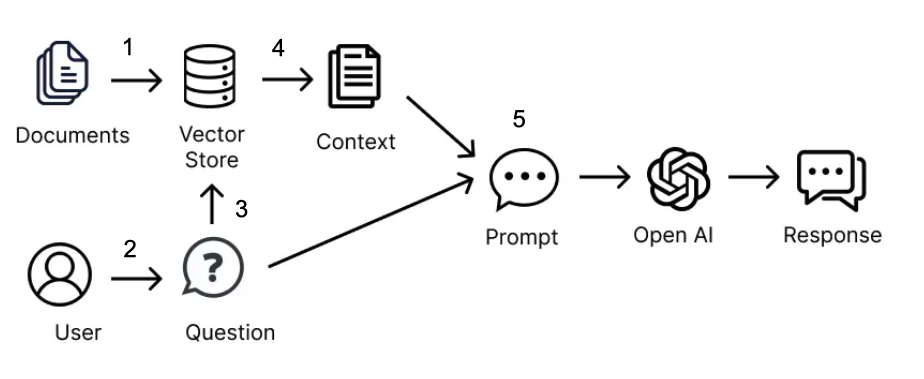
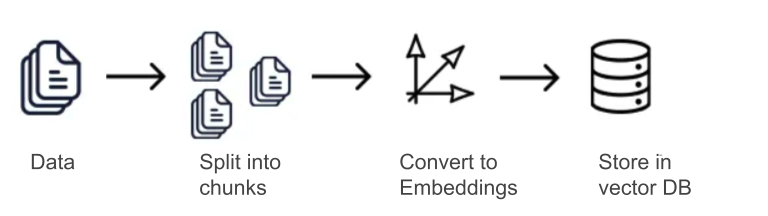
- Data Embedding: First, we generate embeddings for the entire collection of data. This involves transforming the text data into vector embedding representations. Often this involves breaking down the data, such as paragraphs of text, into smaller “snippets” or chunks of data as standalone embeddings that can be individually indexed and retrieved. This technique is crucial for enhancing the efficiency and accuracy of the retrieval process, which in turn impacts the overall performance of RAG models. This step is usually performed up front only one time or only as needed when the underlying collection of data changes.
- Query Embedding: When a user asks a question or provides a prompt, we also generate an embedding for this query.
- Similarity Calculation: We calculate the cosine similarity between the query embedding and the data embeddings to find the most relevant data snippets.
- Contextual Retrieval: The relevant snippets are retrieved based on their similarity scores.
- Prompt Generation: These snippets are included in the prompt to the generative AI, which then generates a response based on this enriched context.
Practical Implementation of RAG
To illustrate a practical implementation of RAG, let’s take the same data set we used in Part 1, the Solution Street blog articles, and apply the RAG technique to this data in order to create a chat application around this previously unknown data. We will use the same open source vector database, Weaviate, to implement this solution. Weaviate actually makes it very easy to implement RAG with built-in support for storing/indexing/retrieving vector embeddings, similarity calculation of vector embeddings, and generative AI prompt generation. It has a pluggable architecture that allows you to plug in different models to calculate the vector embeddings as well as which generative AI model to use. In the following example, we will use the OpenAI embedding and generative AI models (i.e., ChatGPT 3.5), but you can easily swap those out for other models if desired.
RAG Code Demo
Note: if you have already set up the demo from Part 1 of this blog series, you can skip the Setup steps and go directly to the Demo step below.
Setup
All of the code and data that is discussed here is available in this GitHub repo. I will be using Python for this demo. If you want to try this yourself, please have a recent version of Python installed (I am using 3.12.4 here) and sign up for an OpenAI account to get access to the API and an API key. Finally, although not absolutely required, I will also use Visual Studio Code with the Jupyter notebook plugin for this demo with the code from the GitHub repo. This makes it easier to demonstrate each step along the way, and also makes it easier to experiment with the code.
Start by cloning the repo above to your local environment. Now open Visual Studio Code and open the folder where you cloned the repo. It should look like the following:
Note that a “requirements.txt” file has been included with the project that defines all of the dependent libraries for this project. Next, create a Python virtual environment in Visual Studio Code by following these instructions.
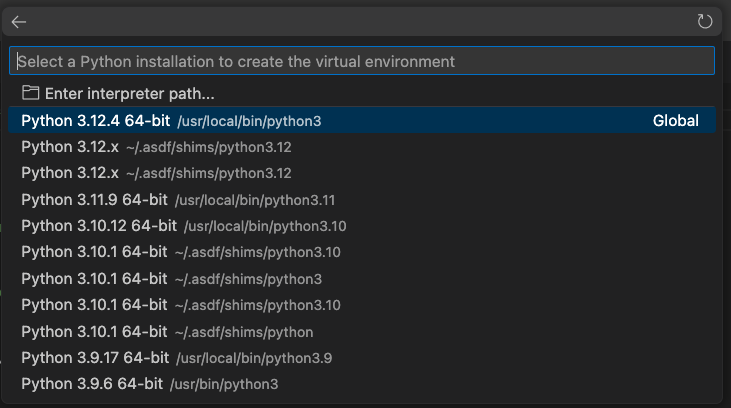
Select the “requirements.txt” file when prompted to “Select the dependencies to install”.

This will install all of the required dependent libraries automatically for this demo.
Alternatively, if you would like to install the libraries yourself, you can open the Terminal view in Visual Studio Code, and install the two required libraries python-dotenv and weaviate-client:
> python --version
Python 3.12.4
> pip install python-dotenv && pip install -U weaviate-client
....
Next, create a new file in the main folder called .env
This is where you can store any environment variables that need to be loaded to run the demos. The Python library you installed earlier, python-dotenv, will be used to automatically load these environment variables in the code. For now, the only variable we need to add to this file is for the OpenAI API key that you set up earlier. Your .env file should look like the following (replace the “xxxxxxxxxxxx” with your API key value):
# OpenAI API Key
OPENAI_APIKEY=xxxxxxxxxxxxDemo
Once the .env file is set up, now open the Jupyter notebook blog-rag-demo.ipynb.
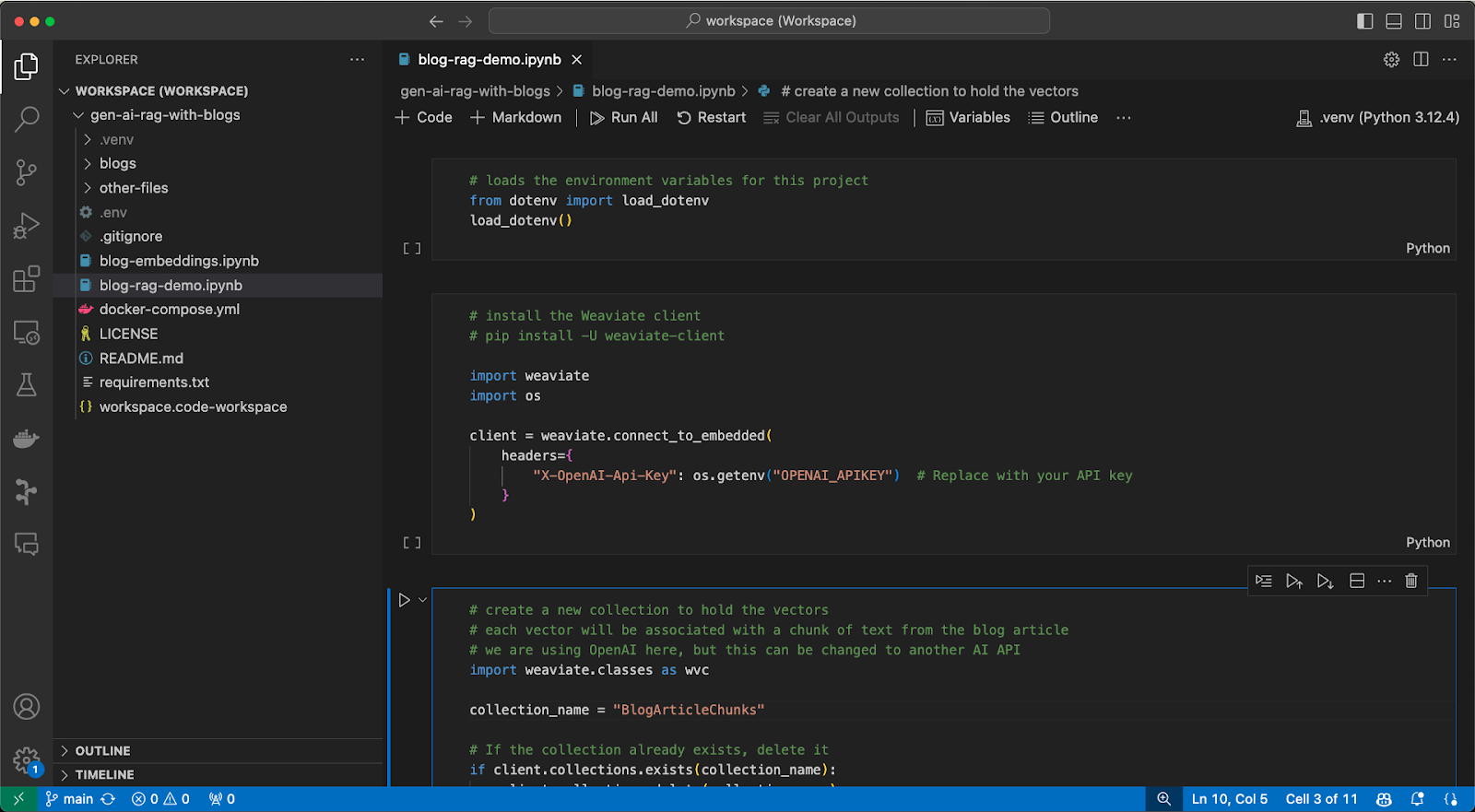
Make sure you have selected the correct Python kernel for the notebook. In my case, this is the Python 3.12.4 virtual environment kernel that I installed the Python libraries into earlier. Let’s now walk through each code block in the notebook one by one so I can explain what is happening and discuss the output.
After running the following code block, the environment variables you saved in the .env file earlier will be loaded for use by the program. Run this code block now:
# loads the environment variables for this project
from dotenv import load_dotenv
load_dotenv()Next, we will initialize and load the Weaviate client. The call to connect_to_embedded() will actually load an embedded version of the Weaviate database that will be used with this program. The embedded version is just for local development. In “real life” you can run the Weaviate database in several ways, including as a Docker container, Weaviate Cloud (WCD) service, self-managed Kubernetes, or Hybrid SaaS. For more information, consult the Weaviate documentation.
import weaviate
import os
client = weaviate.connect_to_embedded(
headers = {
"X-OpenAI-Api-Key": os.getenv("OPENAI_APIKEY") # Replace with your API key
}
)The embedded server will run on port 8079 by default. The output for a successful launch will look something like this:
Started /Users/ghodum/.cache/weaviate-embedded: process ID 33431
{"action":"startup","default_vectorizer_module":"none","level":"info","msg":"the default vectorizer modules is set to \"none\", as a result all new schema classes without an explicit vectorizer setting, will use this vectorizer","time":"2024-07-14T15:40:43-04:00"}
{"action":"startup","auto_schema_enabled":true,"level":"info","msg":"auto schema enabled setting is set to \"true\"","time":"2024-07-14T15:40:43-04:00"}
{"level":"info","msg":"No resource limits set, weaviate will use all available memory and CPU. To limit resources, set LIMIT_RESOURCES=true","time":"2024-07-14T15:40:43-04:00"}
...Note: if you get the following error, you are probably already running a Weaviate embedded instance. Make sure to shut down or restart any Jupyter notebook kernels that may already be executing Weaviate and try again.
WeaviateStartUpError: Embedded DB did not start because processes are already listening on ports http:8079 and grpc:50050use weaviate.connect_to_local(port=8079, grpc_port=50050) to connect to the existing instanceNow that we have created an instance of the Weaviate database, we will now create a collection to hold our blog data. You may remember from Part 1 that collections are groups of objects that share a schema definition and common configuration. In this example, I will create a new collection named BlogArticleChunks to hold the vector embeddings that will represent the chunks of blog article data we will use in the RAG implementation. Three properties will be defined for the collection object to be stored: filename of the file which the blog article data chunk came from, chunk is the chunk of text we are storing/indexing, and chunk_index which is an integer value, starting from 0, which indicates the position of the chunk within the entire file content. Finally, the collection is configured to use the OpenAI text2vec vectorizer to create the embedding and also OpenAI for generative AI features (which will use the ChatGPT 3.5 turbo model by default).
# create a new collection to hold the vectors
# each vector will be associated with a chunk of text from the blog article
# we are using OpenAI here, but this can be changed to another AI API
import weaviate.classes as wvc
collection_name = "BlogArticleChunks"
# If the collection already exists, delete it
if client.collections.exists(collection_name):
client.collections.delete(collection_name)
blog_article_chunks = client.collections.create(
name = collection_name,
properties = [
wvc.config.Property(
name = "filename",
data_type=wvc.config.DataType.TEXT
),
wvc.config.Property(
name = "chunk",
data_type=wvc.config.DataType.TEXT
),
wvc.config.Property(
name = "chunk_index",
data_type=wvc.config.DataType.INT
)
],
vectorizer_config=wvc.config.Configure.Vectorizer.text2vec_openai(), generative_config=wvc.config.Configure.Generative.openai(
temperature = 0.2, # 0 is deterministic, 1 is random
)
)After creating the collection, you should see something similar to this output.
{"level":"info","msg":"Created shard blogarticlechunks_DhZ8sG3UFJX7 in 3.887987ms","time":"2024-07-14T15:52:48-04:00"}
{"action":"hnsw_vector_cache_prefill","count":1000,"index_id":"main","level":"info","limit":1000000000000,"msg":"prefilled vector cache","time":"2024-07-14T15:52:48-04:00","took":91759}Next we will define two functions that will handle the loading and chunking of the blog article data. There are many techniques for chunking data to be used with the RAG technique, but for this example we will use the simple approach of fixed sized chunks of 150 words with an overlap of 25 words. The overlap between chunks helps to ensure that the semantic context does not get lost between chunks.
The chunk_text function takes the blog article text as a parameter and returns an array of chunks. The load_and_process_file function takes the collection and a blog article file as parameters, loads the blog article data, calls chunk_text to chunk up the data, and then inserts the chunk data into the collection. When the data is inserted into the collection, Weaviate will also automatically create the vector embedding that represents that data and will index this vector and the other property data so it can be used for search and retrieval later.
Run the following code block to define the two functions:
import os, glob, re
from typing import List
# chunks the text into smaller chunk_size pieces
def chunk_text(text: str, chunk_size: int, overlap_size: int) -> List[str]:
source_text = re.sub(r"\s+", " ", text) # Remove multiple whitespaces
text_words = re.split(r"\s", source_text) # Split text by single whitespace
chunks = []
for i in range(0, len(text_words), chunk_size): # Iterate through & chunk data
chunk = " ".join(text_words[max(i - overlap_size, 0): i + chunk_size]) # Join a set of words into a string
chunks.append(chunk)
return chunks
def load_and_process_file(collection_name: str, blog_file: str):
blog_article_chunks = client.collections.get(collection_name)
with open(blog_file, mode = "r") as file:
chunks_list = list()
blog_text = file.read().replace("\n", " ")
chunked_text = chunk_text(blog_text, 150, 25)
for index, chunk in enumerate(chunked_text):
properties = {
"filename": os.path.basename(blog_file),
"chunk": chunk,
"chunk_index": index
}
chunks_list.append(properties)
blog_article_chunks.data.insert_many(chunks_list)Now it is time to load the actual blog article data. To do this, we will find each blog article in the example blog directory and then we will call the load_and_process_file function from the previous step. Finally, we will print out the total number of objects we stored in the collection, which will represent the number of chunks we created.
Run the following code block to load the blog article data chunks into the collection (note: this could take some time to complete. On my machine it took about 37 seconds and it created 1180 chunk objects):
# load all the blog files and process them as chunks
blog_files = glob.glob("./blogs/*.txt")
for blog_file in blog_files:
load_and_process_file(collection_name, blog_file)
# print out the total number of chunks in the collection
response = blog_article_chunks.aggregate.over_all(total_count=True)
print(response.total_count)Now that we have the blog article chunk data loaded into the collection, we will now define a function that will implement the RAG technique. Weaviate makes implementing the RAG technique simple by providing several possible built-in methods to execute the various steps of the RAG technique in one easy method call. We will use the grouped task search method collection.generate.near_text here to implement RAG in these examples. This method takes three parameters: query, grouped_task, and limit.
- query is the query that will be run to find other related chunks in the collection (this implements the contextual retrieval RAG step)
- grouped_task represents a question or instruction that the user wants the generative AI model to respond to, the grouped_task value will be added to the prompt along with the context data from the chunks (this implements the prompt generation RAG step)
- limit controls the number of query results (or chunks in our case) of data to be included in the prompt, the actual limit value will vary and will depend on the context window limit of the underlying generative AI LLM model used
Run the following code block to define the rag_query function which we will use to execute the collection.generate.near_text method for our blog article queries:
# define the RAG method
def rag_query(collection_name: str, question: str, group_task: str, max_results: int = 10):
chunks = client.collections.get(collection_name)
response = chunks.generate.near_text(
query = question,
limit = max_results,
grouped_task = group_task
)
print(response.generated)Finally, we are ready to run some queries against the Solution Street blog article data using the RAG technique!
But first, let’s quickly demonstrate the default behavior of the ChatGPT 3.5 LLM that is currently only trained with some general knowledge of Solution Street so that we can see the difference when we apply the RAG technique. I will ask the standard ChatGPT 3.5 interface the following question: “What is Solution Street?” with some additional instructions on how to format the answer:

The result here is general and factually correct, but does not contain a lot of detail.
Now let’s see what happens when we apply the RAG technique with additional context from our blog article data.
Run the following code block:
rag_query(
collection_name,
"What is Solution Street?",
"Summarize the key information here in bullet points"
)You should see a response similar to the following:
- Solution Street is an information technology consultancy based in Northern Virginia
- They help private, government, and non-profit organizations achieve business goals through web applications
- Employees are experts in building web applications using various technologies
- They offer competitive salary, benefits, and a flexible working environment
- Solution Street sponsors NovaJug and partners with Capital Area Food Bank
- They have been in business for 20 years and have made the Inc 5000 list for the 3rd consecutive year
- Solution Street is a Salesforce Cloud Alliance partner and offers career opportunities in various tech rolesWow! Now that answer is a lot more detailed as compared to the default ChatGPT answer. The difference here is that the prompt that was generated also included context data, in this case chunks of blog article data that is semantically related to the question “What is Solution Street?” along with the instruction to “Summarize the key information here in bullet points.” You have just seen an example of the RAG technique in action!
Let’s try another example: there are quite a few Solution Street blog articles that discuss the experiences and lessons learned by our two Managing Partners, Arthur Frankel and Joel Nylund. A lot of these experiences are unique, specific, and personal to Arthur and Joel and are not likely to be found in more general LLMs tuned on publicly available data.
Let’s again ask the default ChatGPT 3.5 interface first:
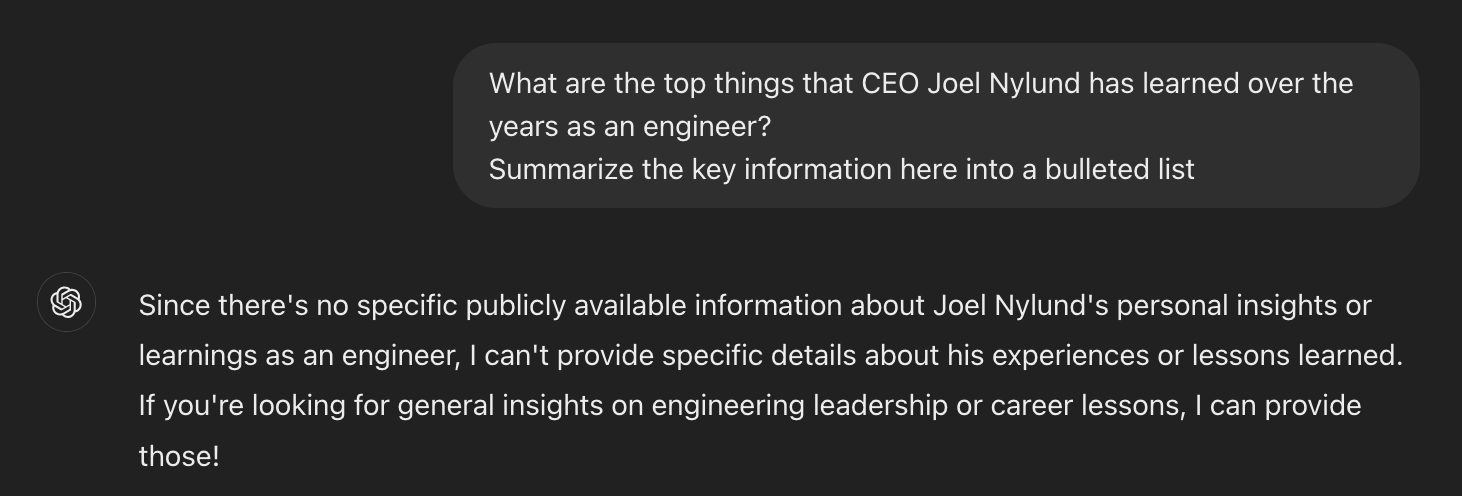
This time the answer is even less helpful.
Now let’s use the RAG technique which uses the blog article data as context and try again. Run the following code block:
rag_query(
collection_name,
"What are the top things that CEO Joel Nylund has learned over the years as an engineer?",
"Summarize the key information here into a bulleted list"
)You should see a response similar to the following:
- Joel Nylund has experience in entrepreneurship, consulting, and software engineering
- Joined forces with business partner Arthur Frankel to start Solution Street
- Emphasizes the importance of being an engineer, not just a coder
- Values such as fairness, respect, honesty, integrity, and kindness are important in decision-making
- Communication skills, teamwork, and using the right tools are crucial for success in software engineering
- Encourages continuous learning and creating a positive work environment for technical staff
- Focus on effective communication and understanding the business problem in software development
- Incorporates core communication skills learned from his father into his consulting interactionsThis time, using the RAG technique, the generative AI model is actually able to answer the question because of the additional context that was provided in the prompt. It is impressive how the underlying LLM is able to summarize the raw blog chunk data that was provided in the context into a cohesive and accurate list.
These are just two basic examples of what we can do with the RAG technique and the Solution Street blog data. I suggest trying a couple of additional prompts on your own to explore more about the RAG technique including:
# additional example 1
rag_query(
collection_name,
"What is Solution Street?",
"Summarize the key information here into question and answer format"
)
# additional example 2
rag_query(
collection_name,
"What are some tips and recommendations for improving client communication?",
"Summarize the key information here into question and answer format as JSON with a question property and an answer property"
)
# additional example 3
rag_query(
collection_name,
"tips for react development",
"Summarize the key information here into a numbered list and include the filename that each tip came from"
)Conclusion
In this two-part series on embeddings and RAG, we’ve explored how these technologies can transform AI applications, from enhancing semantic search to enabling sophisticated generative AI interactions. Part 1 introduced embeddings and their practical applications, emphasizing their role in recommendation systems and content classification. Part 2 introduced Retrieval-Augmented Generation (RAG), showcasing how combining embeddings with generative AI can enable accurate, context-aware responses. By leveraging RAG, applications like custom chatbots and data-driven customer support can provide tailored, accurate information from vast and non-public datasets efficiently.
What we’ve demonstrated here is just the beginning of what RAG can achieve. Imagine applications in legal document analysis, medical diagnosis support, or personalized education platforms—all benefiting from RAG’s ability to retrieve and generate contextually relevant information on demand. As AI models evolve and dataset sizes grow, RAG promises to play a pivotal role in advancing the capabilities of intelligent systems, making them more responsive and adaptable to diverse user needs.
In conclusion, if your company needs help with RAG, embeddings, or even if you are just trying to figure out how AI can help your business, please reach out to us at Solution Street for a free consultation. We can help you!