Business Owners: Take Control of Your Data

At Solution Street we have received several calls and emails from company owners saying something like, “I hope you can help us. We want to replace our team. We hired this other group of developers and we have no idea where the code is or where our data is stored. We’ve never actually seen the database or any of our data except via a few screens.” Historically in a software development process, the business is involved in highlighting the requirements and often laying out some aspects of what data needs to be collected. But once that process has been completed and the web/mobile application has been built, it’s not often that business owners are able to see and use the data for any other purpose besides the specific use of the application. This severely limits the business owner. What if the business owner can use that data to help make future business decisions?
With many business systems, much of the data is hidden from the business. Even if the data is stored in a relational or noSQL database, typical business users only see the data via processing screens. These can be CRUD screens or reports or something similar. With the tectonic shift of the new AI era, there is a strong paradigm change away from the focus on processing to the focus on data. With this new focus, software engineering firms will be putting customer data in the hands of business owners to help make incredible strides in the business rather than the processing. What will the business owners see?
To begin with, they will see the raw data and how it must be “cleaned” or formatted. Sometimes business owners are shocked to see how poorly their data is stored. Maybe there is missing data. Maybe there is data that has not been collected. Software applications sometimes hide poorly stored data in databases. As many data scientists would tell you there is an enormous amount of time devoted to just cleaning data before using it. By removing the curtain, business owners who are often most familiar with the data collected, can first see and point out data that needs to be appropriately formatted, missing data, or even inaccurate data.
Once the data is visible and “cleaned,” the business owner can use any of the great tools now available to help analyze the data. Let’s take a look at Simple ML (Machine Learning) for Google Sheets. This tool simply and elegantly lets the user do some very basic, yet powerful and easily executed tasks for things like prediction. Business users, with basic experience in Excel or Google Sheets can not only have a good look at their data, but “play around,” forecast, and make data-driven decisions which can actually yield something useful for both short- and long-term planning.
Let’s take a look at an example that could easily be recreated by any business or product team member even without any experience in AI or Machine Learning.
- First, let’s get Simple ML for Google Sheets in your environment. Just install this free extension.
- Next, let’s get some basic business data from Kaggle. Kaggle is a data science/Machine Learning website that has a large number of free datasets that data scientists use for study and practice. We are going to use this one related to e-commerce shipping data. Click on the download button on the page to download the csv file. You may need to create an account, but it’s free. You can read the details including the information on the columns of the dataset on the website, but here is the brief description: “An international e-commerce company wants to discover key insights from their customer database. They want to use some of the most advanced machine learning techniques to study their customers. The company sells electronic products.”
- Now let’s ask Google Sheets to upload the csv file you just downloaded from Kaggle. Do this via the (+) New -> File Upload link in Google Drive. After that, click on the menu item Extensions -> Simple ML for Sheets -> Start. After uploading the data and starting Simple ML for sheets, you should have something that looks like this:
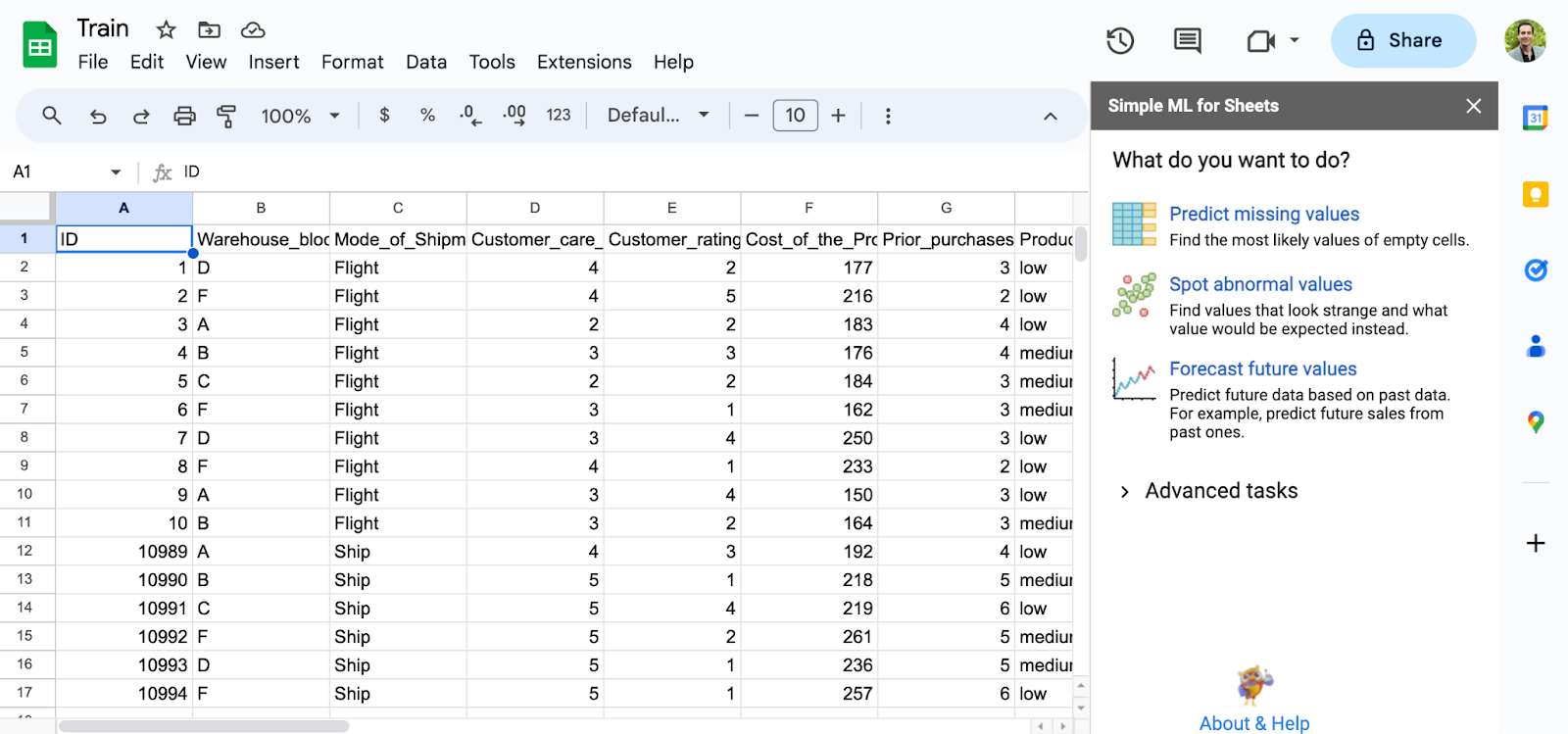
- If we just look at the data we can see that the last column, column L (Reached on Time Y/N), represents whether the package reached the customer on time. 1 is yes, 0 is no.
- Here you can see that you can perform several important tasks that can either be used by IT for cleaning up data, or more importantly for the business to be able to spot abnormalities or forecast future values. Feel free to play around with those options but I would rather try something somewhat more advanced. Let’s click on the Advanced tasks drop down and select “Train a Model.”
- First, before we get to that, here’s the quickest-ever primer on Machine Learning! We are going to have the system load all of this e-commerce data into a model to train it. We can then use that model to predict potential outcomes that may help us determine if the package is going to be late or not. The model does this based on columns in the spreadsheet. We are going to create a classification model using supervised learning. All of the columns in the Google Sheet are variables (features) used to train the model except column L (Reached on Time) which is called the target (label). Once the machine trains on all of this data we can give it new/unseen/sample data to allow it to give us its prediction on whether or not the package will be late. Phew, that was a quick introduction. For more details see here.
- Back to training a model. You should see what I have below when you train the model. The Label should show Reached on Time automatically and if you expand the source columns it should show the rest of the columns. Now, an important point is that something like the ID column should have absolutely no impact on the model’s prediction since the ID column appears to be just a sequential number that has no relation to whether or not the order is received on time. This is an important point. As a business owner you would likely know whether or not other columns have any part of the business process and you can exclude them in the model. Here we will exclude the ID column by not selecting it in the “Source columns” dropdown selection.
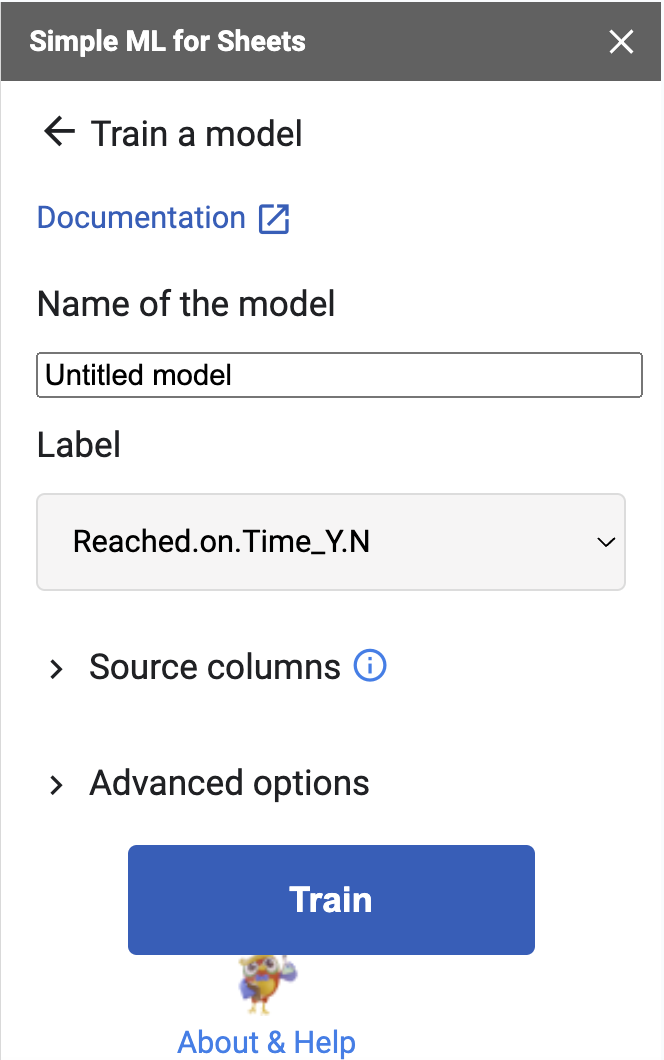
- Once you have trained the model (with 10,994 rows of data) we can now make some predictions. Note that with machine learning, models are created using the vast majority of available data but some of the data is also used to validate the model. The system will provide a percentage prediction rather than a boolean (yes/no) prediction. In the case of our example, “Reached on Time” should be a 1 or 0, but the system can only provide the percentage between 0 and 1 it believes to be the answer. To illustrate this, I will use the image below representing a different target/label than the one in our example (image source: https://www.freecodecamp.org/).

What do you see here? A muffin or a chihuahua? You might be able to figure out the correct answer for each image, but a machine will provide the percentage prediction for each image. For example, the predicted result for the first image in the top left corner is .933 or a 93.3% chance that the image is a muffin.
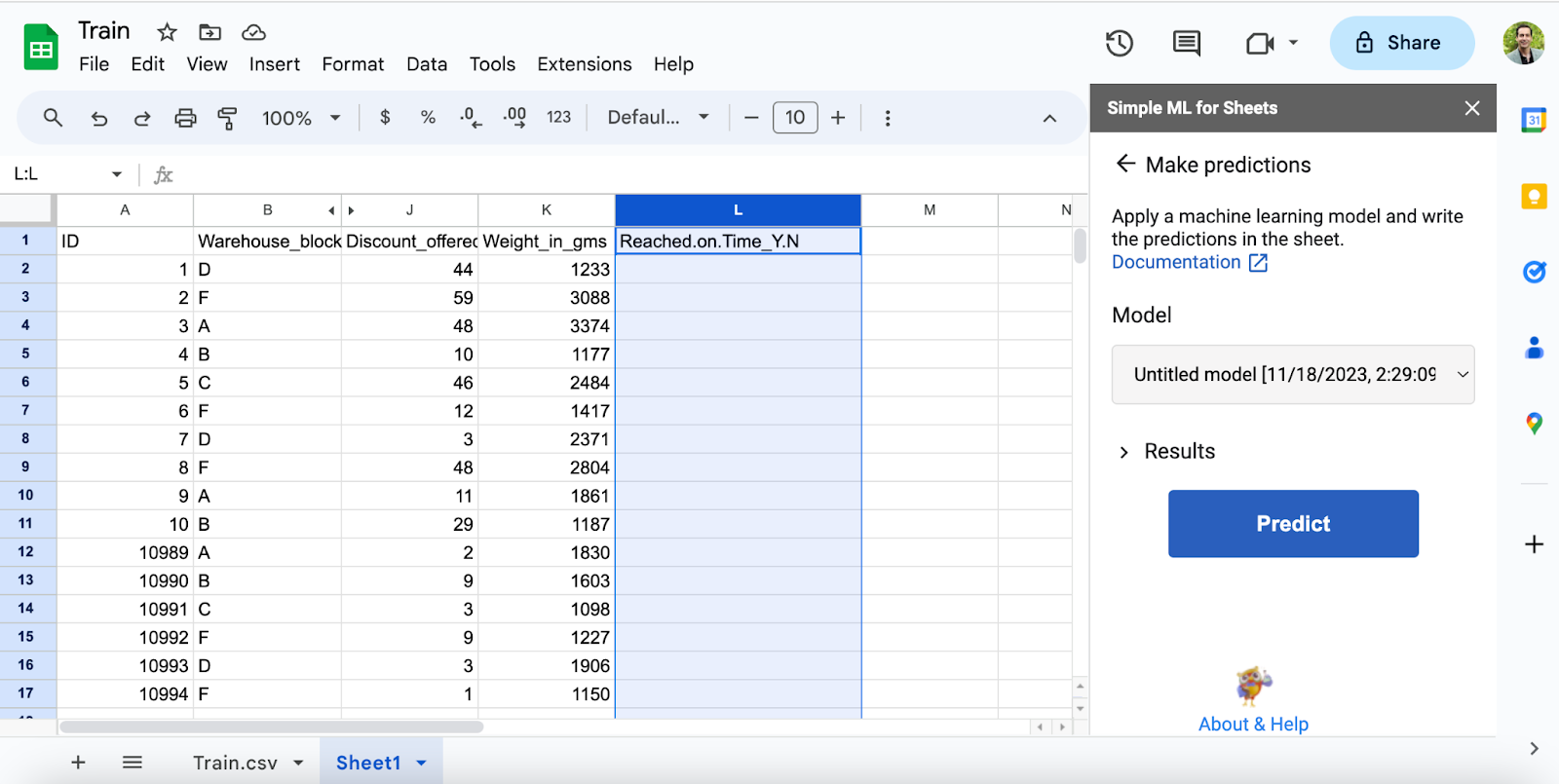
- Now create a new sheet (new tab in your current Google Sheet) and copy over some of the rows of data including the header from the original sheet to the new sheet. You can take data anywhere from the original sheet. I took 10 rows from the top and several from the end. Delete the data from the Reached on Time column and press the “Predict” button to predict the “Reached on Time” value. Note: In the image below I have hidden some columns for ease of display.
After you press the Predict button you will see a new column M with the predictions. Again, the number will range from 0 to 1 where you can assume that something over 0.5 has a prediction of 1 (reached on time) and something less than 0.5 has a prediction of 0 (not reached on time).
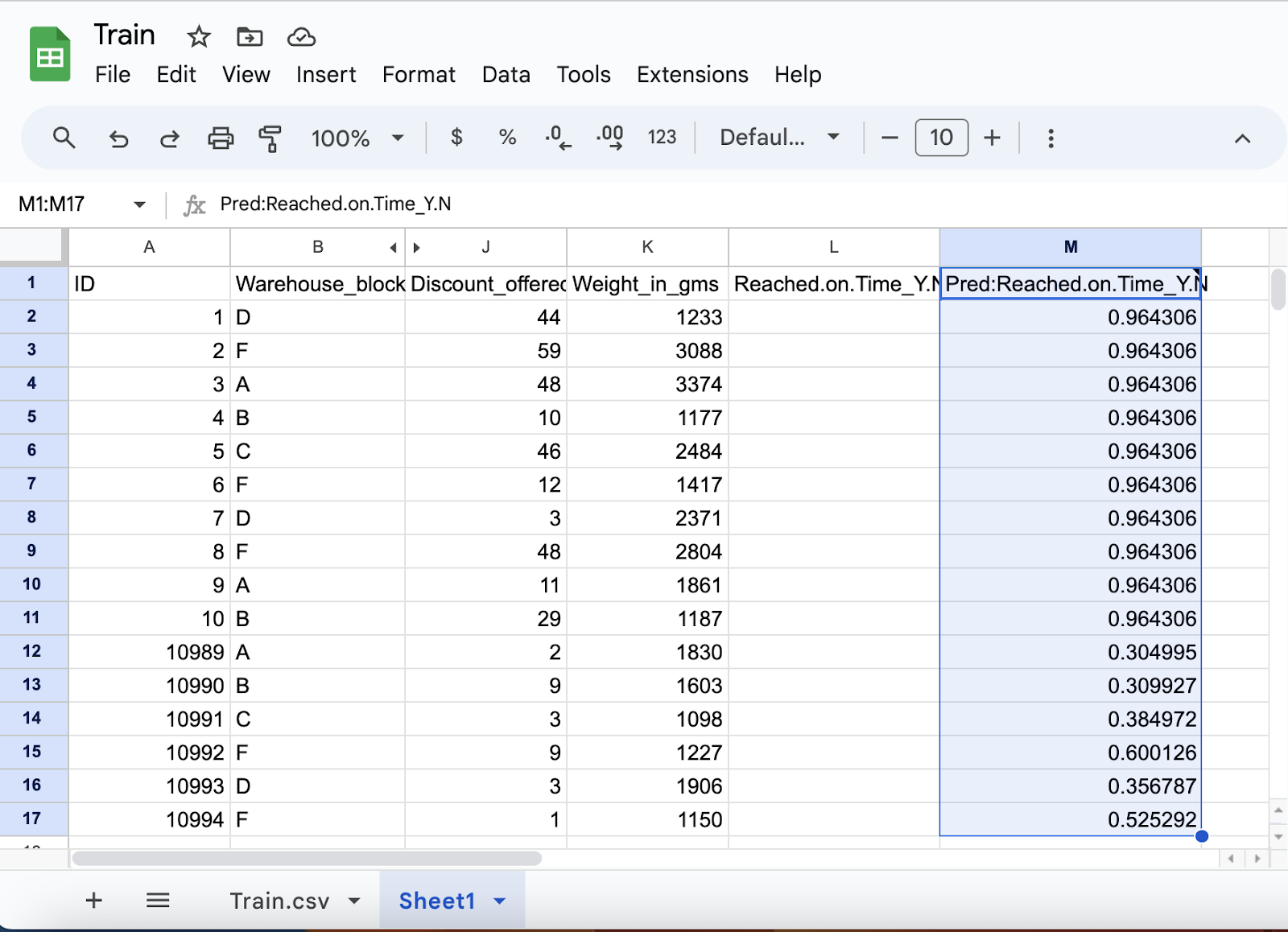
And business users can easily see this in chart form:
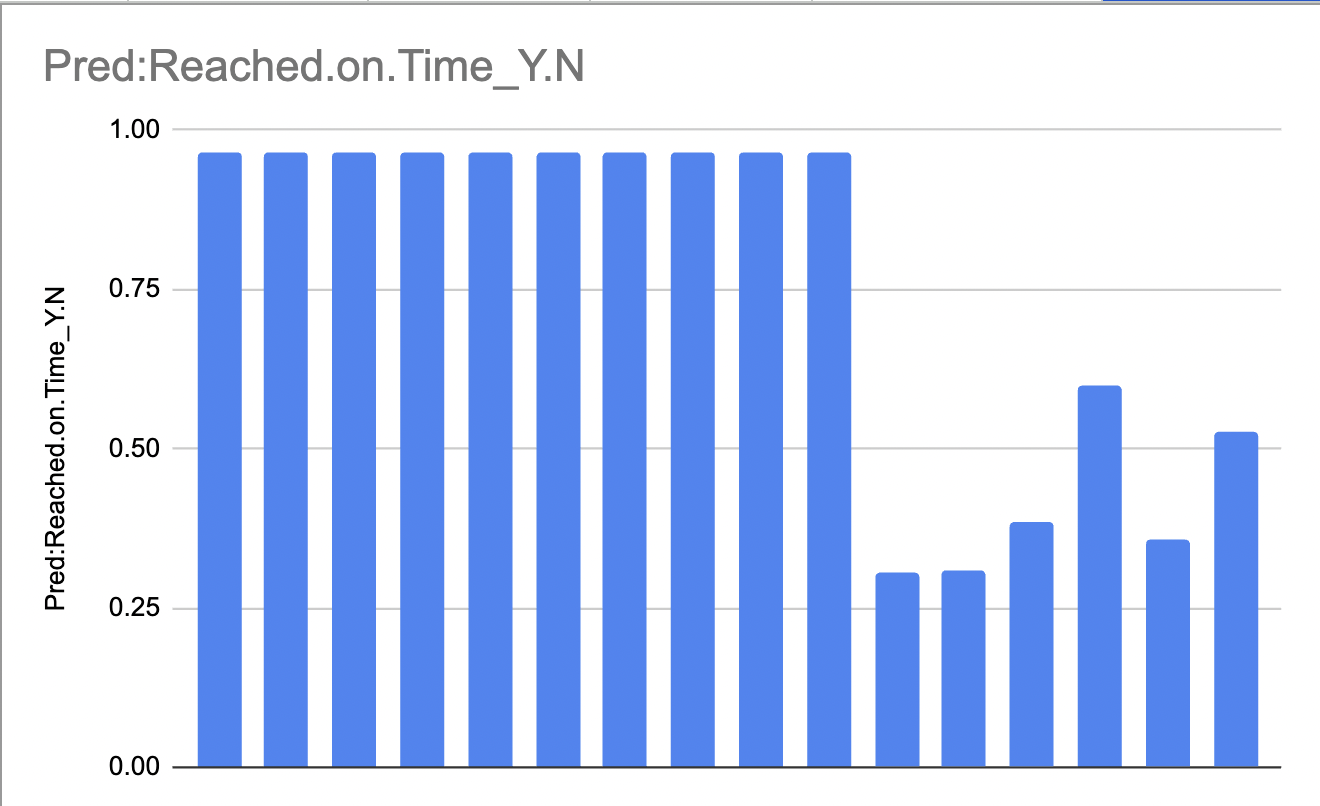
- Of course since we haven’t changed any of the variable/feature data from the original data from Kaggle, the model should have an easy time to make valid predictions, but feel free to change any of the column data or start with new data to play around with what might happen.
Often when dealing with raw data, ensuring the right data and quality data is a time-consuming process. In traditional business systems, many databases store the data needed for the processing, but not necessarily data that might help business decisions. This is the crux of the shift. By allowing the business to view, understand, and model the data collected, they can assist with pointing out inconsistencies, needed additions, variable/data importance in creating models, and most importantly changes in direction for the processing of the data that directly benefits the business. This gives the power back to the business owners.
Solution Street has been working to empower our clients by providing them access to and, more importantly, use of their data. Besides yielding better business results, this is a purer relationship between client and vendor where the client is fully aware of not only the processing of its systems, but the actual data being collected and how that data can best help them.
Reach out to us here at Solution Street if you want to use AI and take control of your data.