You Really Should Be Using GraphQL

Origin of GraphQL
Back in 2012, Facebook was dealing with an issue that many of us software developers who build products with multiple front-ends (web and mobile) must address. How can we build a server component Application Programming Interface (API) that works seamlessly with both mobile and web applications? How can we have the same API calls with the same data response easily handled by web and mobile and be performant? The result of Facebook having difficulty with these questions was the creation of GraphQL by Facebook with a specification, open source code, and a community. GraphQL not only provides a solution for the different requirements of web and mobile, but also the ever increasing need to have a somewhat generic API access to systems.
GraphQL vs. Rest
Many of us have used Representational State Transfer (REST) for a while and understand that it’s an architectural style. REST refers to a set of principles like statelessness for developing APIs. It uses HTTP verbs/methods like GET, PUT, POST to link resources to actions.
If you take a banking application with an object like a banking transaction you may have the following REST API call (endpoint) which returns the Transaction along with the name of the associated Account (i.e., attributes of its parent).
1 2 3 4 5 6 7 8 9 | GET /transactions/1234 { "date": "2019-05-12", "amount": 100.50, "account": { "name": "My Checking" } } |
This object (or resource) is coupled with the way you retrieve it. Here we are retrieving a banking Transaction with the id of “1234” based on the URL pattern and we have defined on the server that when we retrieve the Transaction we will bring along with it the name from the associated Account. We have essentially denormalized a bit of Account data for the call and determined that this would occur on the server.
GraphQL is really an extension of REST, but the key difference is that the resource is decoupled from the way you retrieve it. In GraphQL there is the resource AND then there is the action (the example below uses a Query as the action). Here we define the resource and the action separately where Transaction and Account objects are the resources and the Query type defines basic ways you can retrieve the resources:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | type Transaction { id: ID! date: Date! amount: Float! account: Account! } type Account { id: ID! name: String! balance: Float! transactions: [Transaction!]! } type Query { transaction(id: ID!): Transaction account(id: ID!): Account } |
// Note that the exclamation point (!) above represents required – cannot be null
Then the GraphQL call in basic URL form is as follows:
1 2 3 4 5 6 7 8 9 | GET /graphql?query={ transaction(id: "1234") { date, amount, account { name } } } { "date": "2019-05-12", "amount": 100.50, "account": { "name": "My Checking" } } |
In this very simple case above, we are comparing using a GET method for the specific REST call vs. a generic Query method for the GraphQL call. Using the above GraphQL call we can select which fields we want to retrieve from our client application. Therefore, while we are “stuck” with the REST call returning only the name of the Account since that was determined on the server when we implemented the REST call, we have the flexibility of selecting more fields from the Account (e.g., balance) if we prefer when we execute the call from the client without changing any server code. We can expand this example in many facets by adding or subtracting fields and hierarchical objects we are retrieving. Herein lies the major benefit. We no longer need to establish the returning schema on the server knowing that we may need to handle different front-end clients with different requirements for data including fields and levels of data in a hierarchy.
Why GraphQL?
You should already see the major benefit of using GraphQL – its ability to allow the client to define the fields and hierarchies to return without changing the server definition and multiple roundtrips to the server. Those of you who have done many RESTful applications understand that typically you may need three calls to the server before getting the data you need for a single page.
In my examples that follow, I will continue with a fictitious banking application in which there are Customers who have one or more Accounts and those Accounts have zero or more Transactions. Note that an Account can have one or more Customers (think joint account) but a Transaction can only belong to a single Account.
Figure 1.

Figure 2 shows a mockup of a single web page displaying a Customer’s information along with a list of their Accounts followed by the most recent three Transactions for a selected Account.
Figure 2.

Using REST we may have situations where we need three or many more calls to the server:
- /customers/1 – retrieve some information from the customer with id of “1”
- /customers/1/accounts – retrieve that customer’s accounts
- /customers/1/accounts/123/transactions – for each account, retrieve the most recent three transactions
In GraphQL there is only one API and that API is controlled by the client so the client can make a single call to retrieve all of the required data including the Customer information, the Accounts, and the most recent three Transactions for each Account. In a traditional REST API environment, how would your REST call be implemented for retrieving the most recent three transactions? Would you have a single REST call to perform all of these three by essentially denormalizing your data and creating a non-REST API? What if you had different client access requiring different sets of data? Developers typically work around this problem by creating more and more REST calls to appease the client and over-fetching data.
The main benefits of GraphQL are:
- Hierarchical – the GraphQL client can request data in a hierarchical form including multiple data items from different parts of a hierarchy with a single call.
- Strongly Typed – since the GraphQL schema is strongly typed, descriptive error messages can be provided with incorrect client calls.
- Introspective – a GraphQL server can be queried for its schema/API.
- No Versioning – for many traditional RESTful applications, changing the server call to accommodate the client requires a change in the version of the server API and informing the clients. With GraphQL you can add new schema functions without change on the client and you can deprecate other functions but still allow them to function.
Tools and Libraries
There are a number of tools and libraries available for GraphQL for all stacks. This includes the Java stack, Ruby on Rails, Python/Django, and of course JavaScript/NodeJS. I’ve only tackled GraphQL in the JavaScript/NodeJS stack so far. This website that I found provides the clearest view of what libraries exist for each software language at each part of the stack.
With respect to my example banking application I am using a NodeJS server with graphql-yoga library to handle client calls. This package is built upon Express and has a powerful and pleasant web playground to execute actions to the server. In addition, I am using Prisma as a data layer to provide a pretty expressive ORM that works with SQL and noSQL databases and handles GraphQL calls with simplicity. This ORM autogenerates (no code is generated, but the functions are there) all of the CRUD processing similar to Rails for those of you who have used Rails. It also provides a type-safe client.
Now when I first was using this architecture I was confused a bit, so let me see if I can explain it simply. In this architecture we can have a web or mobile client executing GraphQL calls which calls to our node server running graphql-yoga which then (by using what’s called resolvers), handles authentication, authorization, and any business functionality and uses our Prisma server for data access – i.e., we have client->server->server.
Since there is much complexity of a graphql function (i.e., so many different possibilities) having an ORM like Prisma is very useful since all of the permutations are handled for you. Any tool like Prisma has its downsides and I will discuss those later.
Here is our datamodel.graphql file to define our banking application resources. This file is used by Prisma (our ORM):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | type Customer { id: ID! @unique firstName: String! lastName: String! email: String! @unique accounts: [Account!]! @relation(name: "CustomerToAccount", onDelete: CASCADE) } type Account { id: ID! @unique name: String! balance: Float! owners: [Customer!]! @relation(name: "CustomerToAccount", onDelete: CASCADE) transactions: [Transaction!]! @relation(name: "AccountToTransaction", onDelete: CASCADE) } type Transaction { id: ID! @unique date: DateTime! amount: Float! cleared: Boolean @default(value: "false") account: Account! @relation(name: "AccountToTransaction", onDelete: SET_NULL) } |
Again this is defining a Customer with a many-to-many relationship with Accounts and Accounts having a zero-to-many relationship with Transactions. Prisma will generate the database based on the data model above.
Here you can see the generated tables in my Postgres database:

Note that even though one of our relationships is a one-to-many it still generates a cross-reference table.
As mentioned before, GraphQL separates the resource and the actions. Above in our datamodel.graphql file we defined the resources and in GraphQL we also need to define the actions (i.e., the allowable actions by the client). These actions are defined in a schema.graphql file as follows for my examples:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | type Mutation { createCustomer(data: CustomerCreateInput!): Customer! createAccount(data: AccountCreateInput!): Account! createTransaction(data: TransactionCreateInput!): Transaction! updateCustomer(data: CustomerUpdateInput!, where: CustomerWhereUniqueInput!): Customer updateAccount(data: AccountUpdateInput!, where: AccountWhereUniqueInput!): Account updateTransaction(data: TransactionUpdateInput!, where: TransactionWhereUniqueInput!): Transaction } input CustomerCreateInput { firstName: String! lastName: String! email: String! accounts: AccountCreateManyWithoutOwnersInput } type Query { customers(where: CustomerWhereInput, orderBy: CustomerOrderByInput, skip: Int, after: String, before: String, first: Int, last: Int): [Customer]! accounts(where: AccountWhereInput, orderBy: AccountOrderByInput, skip: Int, after: String, before: String, first: Int, last: Int): [Account]! transactions(where: TransactionWhereInput, orderBy: TransactionOrderByInput, skip: Int, after: String, before: String, first: Int, last: Int): [Transaction]! customer(where: CustomerWhereUniqueInput!): Customer account(where: AccountWhereUniqueInput!): Account transaction(where: TransactionWhereUniqueInput!): Transaction } type Subscription { customer(where: CustomerSubscriptionWhereInput): CustomerSubscriptionPayload account(where: AccountSubscriptionWhereInput): AccountSubscriptionPayload transaction(where: TransactionSubscriptionWhereInput): TransactionSubscriptionPayload } |
This file above is generated by Prisma and then altered, imported, or reused in part by the GraphQL yoga server to limit what the client can do. Above we can see queries defined along with mutations and subscriptions. You can ignore some of the complexity of the parameters above within the functions, but understand that this is where you are defining your actions along with the data being fed and returned from those actions. Anywhere there is a resource mentioned (i.e., Account), GraphQL automatically allows you to walk up and down that hierarchy.
Setting Up Data for My Examples
Typically, with many applications we have relationships in our data ranging from simple to complex. To display and explain certain GraphQL statements in the following sections I’m going to use our fictitious bank data model of a Customer having a many-to-many relationship with Accounts (e.g., two people are joint owners on multiple accounts) and a one-to-many relationship between Accounts and Transactions whereas an Account can have zero or more Transactions.
Within GraphQL there are three different execution concepts:
- Query – retrieve data
- Mutation – create, update, and delete data
- Subscription – publish/subscribe model to be notified when data changes, typically implemented with WebSockets
I have created a simple application using graphql-yoga and Prisma using the resource and action files above. I did not have to write much code at all. This shows the simplicity out-of-the-box, but more code would be required to deal with things like authentication, authorization, and just plain old business logic on the server. This code is handled within resolvers within the graphql-yoga server.
I have deployed my code to Heroku and you can get to the running server using this link. Since it’s running on Heroku using the free version it may take a minute to start node and Prisma each and then execute its first function. Once you get there you will see the GraphQL Playground where you can follow along with the examples below and implement your queries, mutations, and subscriptions.
The GraphQL Playground (moving forward I’ll just refer to this as playground) looks like the following. Note: The “play” button in the images does not represent videos. This “play” button is used by the playground to execute the mutation, query, or subscription.

You can clear the comment line from the left side and type away. You can create your own data and retrieve it. Two important notes when using the playground (or really a GraphQL client) and the default setup with GraphQL/Prisma:
- When you query any resource/object you must provide at least one attribute to query. So if you are querying Customers you must ask for at least one attribute. It doesn’t default to every attribute. When you are querying for the Accounts within the Customer you also need to specify at least one attribute to retrieve.
- When you are mutating data (create, update, delete) you must return at least one attribute from the resource/object. If I update Account, I must return some attribute of the object.
You will see this in the examples below.
Create, Update, Delete
First let me start with Mutations – Create, Update, and Delete – since I need to show how the data gets into the database.
Using our fictitious banking application I would first need to create some Customers so using the playground we can easily populate the database and validate the functions. Later we will discuss using a JavaScript client (e.g., a React front-end), but the playground is very useful for basic testing of the API. As a side note, the playground can display the schema and documentation from its right side tabs as shown below.

Below I am just creating two Customers (“Arthur” and “Joel”) and can see the resulting id.


If we try to execute the last mutation again, we will receive an error due to the “@unique” constraint defined on our email field in our data model for Prisma.

There are constraints like “@unique” and others that are handled at the ORM level and then all other control (authentication, authorization, business logic) is handled by the nodeJS server.
Now that we have two Customers in the database we can create a new Account and add those Customers to the account. I will do this in two separate functions to show a create then update, but this can be performed with a single call to createAccount.


As a reminder, the data required for “input” in our functions is required (or not required) based on the schema, but the data returned after the function executes is optional (as we see here with name, balance, and owner info). We always need to return something and if we return a subnode (as in the case of “owners”) we need to have at least one attribute returned.
At this point we have two Customers and one Account with those Customers as owners (i.e., Joint Account) in the database.
Now we can add a Transaction to the Account.
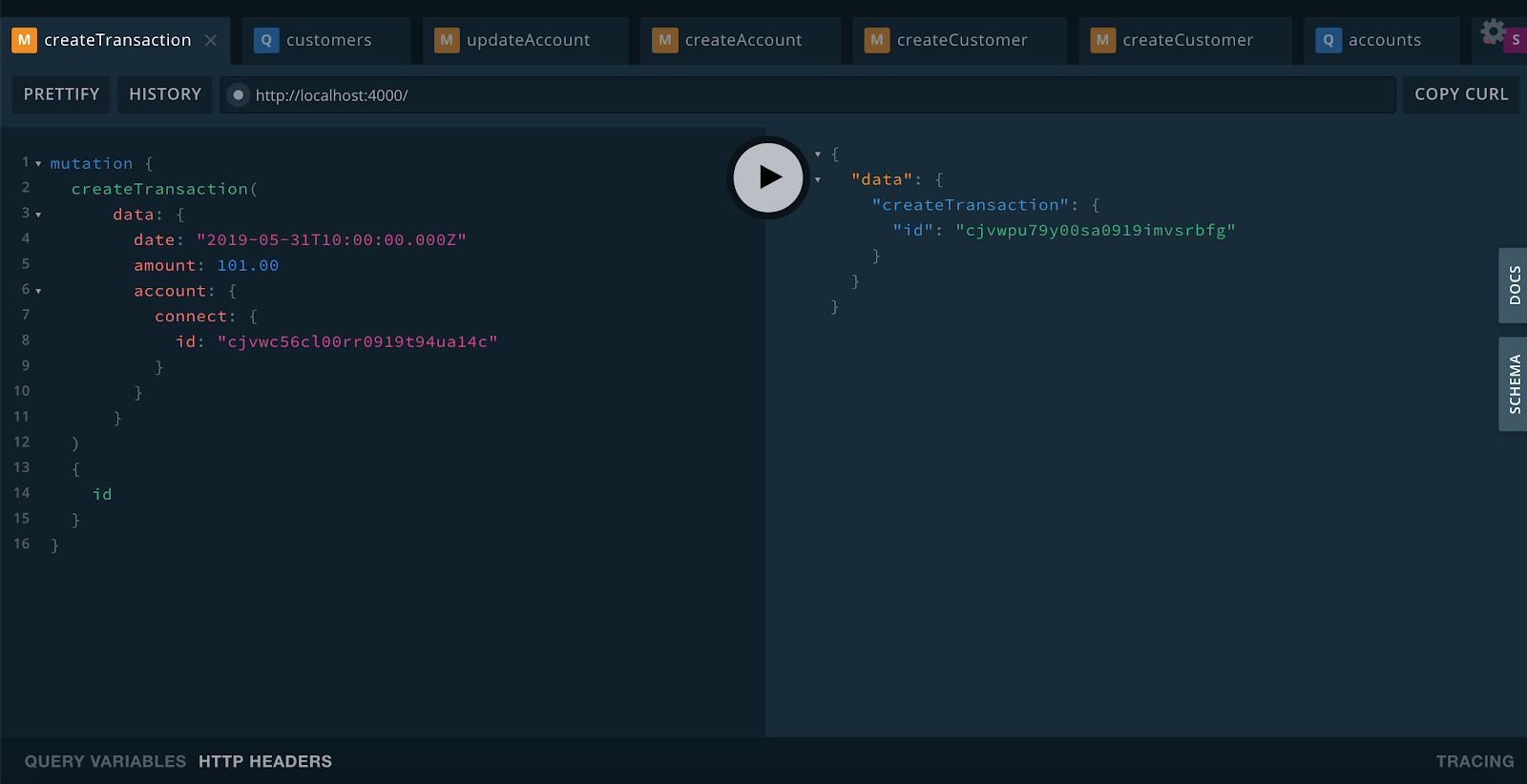
Here you can see that we added the Transaction with the id of the Account we created previously.
At this point in our database we have two Customers, a shared Account with a single Transaction. Each of these functions that I executed above within the playground would typically be executed from a client GraphQL library. Now let’s take a look at how to query the information. Note that I did not show delete functionality since I have limited them in my schema.graphql file (i.e., they are not in that file so they are not permitted). Depending upon the application, you may want to limit certain functions or not.
Query
First let’s just get a list of our Customers. Here we can see in the playground that we are using our “query” keyword instead of our “mutation” keyword to start the command.

Here, when we query for an object we can list the attributes we want to be returned (or not be returned).
In the following, we can see how the client can filter the results by searching for a Customer that contains a certain lastName. This example provides a simple filter, but the filters can be complex and also include sorting and pagination.

Of course the powerful aspect of GraphQL is displayed here where we are retrieving a hierarchy of data. We are retrieving all Customers with Customer attributes, all Accounts for those Customers with Account attributes, and all Transactions for those Accounts with Transaction attributes. (Note that in the image we can’t see the full data including the second Customer’s full information.)

Given a traditional RESTful server implementation this would typically be three separate calls, but even if it was a single call the specific attributes returned are predefined on the server. In contrast, with GraphQL the client determines the data requested.
Coming back to the original example of requiring the data needed for the mockup in Figure 2, you may have a GraphQL query as follows:

Here we are asking for a specific Customer based on the ID and also getting the last three Transactions to display by using the “last” and “orderBy” keywords. If the user interface changes or there is a different user interface you can see how you can easily change the query to accommodate the fields on that webpage or mobile device.
Subscriptions
Another very powerful aspect of GraphQL is Subscriptions. This follows the traditional publish/subscribe model. We can use Subscriptions in any business application to notify the client when data is added or changed in the database.
Here we can define a simple Subscription to notify the client when any modification (create/update) to a Transaction occurs. When we execute this you notice that the playground is in wait mode and displays “Listening…”

Now once we create a new Transaction…

the original playground tab listening for changes is still listening but notifies the user that a new Transaction was created:

Again within a client library (e.g., React, Angular, Vue) this can be a powerful addition.
At this point we have discussed Mutations, Queries, and Subscriptions and have shown examples using the playground. A traditional application would have a client front-end (web or mobile) and use something like a GraphQL client such as Apollo and integrate this library within something like a React/Angular/Vue front-end.
N+1
When I first started looking into GraphQL I was immediately thinking about the N+1 problem – where you may be performing exponentially more queries needed for each sub or parent node. Using our banking application example, fetching the Accounts and getting the owners of each Account (i.e., Customer objects) may require many queries. Getting the Accounts may be one SQL statement, but then there is a request for a Customer(s) associated with every Account. This could easily lead to another request for every Account (i.e., N+1). With ORMs like Prisma, this is a concern, but really even if you were hand-rolling an ORM, this would always be a concern.
With REST this is certainly a problem but you can predict the call since the server REST call is static. With GraphQL the N+1 problem is further exacerbated because the server cannot predict how expensive the request will be before it’s executed. The solution to this is the dataloader library. You can implement solutions for dataloader within your resolvers when you come across problems. Dataloader is part of Prisma and therefore (it allegedly) is safer from the N+1 problem. In Prisma there is a logging level that allows you to dump the SQL statements to monitor the number of SQL statements executed.
As with any ORM you need to be careful of these situations and I am just pointing out that this problem is broader with a GraphQL server API.
GraphQL Client
Using GraphQL on the client comes in many forms/libraries, but I wanted to provide a very simple example to show how a query is executed on the client.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | import ApolloBoost, { gql } from 'apollo-boost' const client = new ApolloBoost({ // pointing to my GraphQL server on heroku uri: 'https://afternoon-island-18488.herokuapp.com/' }) // same type of query we see in the GraphQL Playground const getCustomers = gql` query { customers { firstName lastName } }` client.query({ query: getCustomers }).then((response) => { let html = '' response.data.customers.forEach((customer) => { html += ` <div> <h3>${customer.firstName} ${customer.lastName}</h3> </div> ` }) document.getElementById('customers').innerHTML = html }) |
I’m using Apollo Boost (barebones – typically you would use extra libraries for integration with React or similar front-end frameworks). Here is my code on GitHub which you can clone, install, and execute.
So Why Aren’t We All Using GraphQL?
When I first started looking into GraphQL I was very impressed. It’s pretty easy to see how it solves an important issue of replacing static REST calls dictated by UI changes with a very dynamic hierarchical data retrieval. I also could see the benefit of using GraphQL as an API engine to deal with an issue we have here at Solution Street – lots of applications require custom reporting to handle all sorts of data requests. Using GraphQL is a much more dynamic solution to allow client access to data with the freedom to retrieve what is wanted without server changes.
If you look at the history of API development, not too long before REST and GraphQL was Web Services…and yes, they are still used today. With the SOAP protocol and using XML, Web Service APIs are defined and called in a verbose way as defined by the server. The benefit with Web Services is the detail-oriented aspect of the API and the server flexibility of the API. REST became the de facto choice after Web Services because of its simplicity and convention. Any developer could join a new project and immediately understand the APIs. Unfortunately many developers go outside of the convention of REST and create APIs that cater to the User Interface and muddy the waters. GraphQL may not have the simple convention that REST does, but it provides a dynamic, flexible interface that has the ability to be directed by the client (User Interface) unlike REST and Web Services.
With all of the positive aspects, I have run into several items which I believe are at the core of why we aren’t using GraphQL.
- It’s harder to implement even with using Prisma as an ORM. Although Prisma gives you a whole lot without any code, in a real-world situation there is a lot more to do. If you want to actually implement authentication and authorization as part of the CRUD calls you can implement your needs and then call “up” to Prisma, but it’s still not that easy. If you are not using an ORM like Prisma, implementing all of the database calls within every resolver and handling every aspect of the hierarchy is certainly more difficult than standard REST.
- It’s confusing to figure out what you need. As mentioned, this website helps you identify the pieces, but even on this website it’s confusing to know what you need and where it fits in your architecture.
Like all technology, this is evolving and will hopefully be simpler. Even with these items above, I would use GraphQL to create an enterprise application with multiple client types (web, mobile, API). I like that it solves a problem and with the ever-changing aspects of user interfaces, having a dynamic server API is very powerful.